Machine learning has been a critical capacity for modern business. According to Technology Magazine, the top 10 companies in the world of machine learning will grow to nearly $2tn by 2030. Companies such as Amazon, Google, and Microsoft have been the leading force to develop cutting-edge machine learning solutions for business problems with corporate and customer data. For business students, we want to discuss what are the key ideas in machine learning algorithms, in what ways are machine learning algorithms different from human intelligence, and what are the key challenges to integrate machine learning into important business applications.
However, at the very beginning, we want to start with this post to provide a brief history of machine learning. Just like machine learning algorithms need the so-called training data to program itself to make human-like decisions, we humans should also look at important history processes to understand why certain ideas can evolve into general-purpose technologies, and what would happen in the future.
There have been many articles discussing the history of machine learning. Instead of repeating them, we want to describe main changes of machine learning development from these aspects: theories, software, hardware, and data.
Theories
The major task in machine learning is called supervised learning, which aims to learn a function between some input X and some input Y. The learning process will fit a function of certain form to observed training data, i.e., pairs of (X, Y). If the function to be learned is complex, more data is needed. To process data at large scale, more efficient software and hardware are needed. Therefore, the different aspects (theories, software, hardware, and data) of machine learning history cannot be independent.
The most simple function we can learn in the supervised learning problem is a simple learner regression, which is a straight line (or hyperplane for high dimensional X).
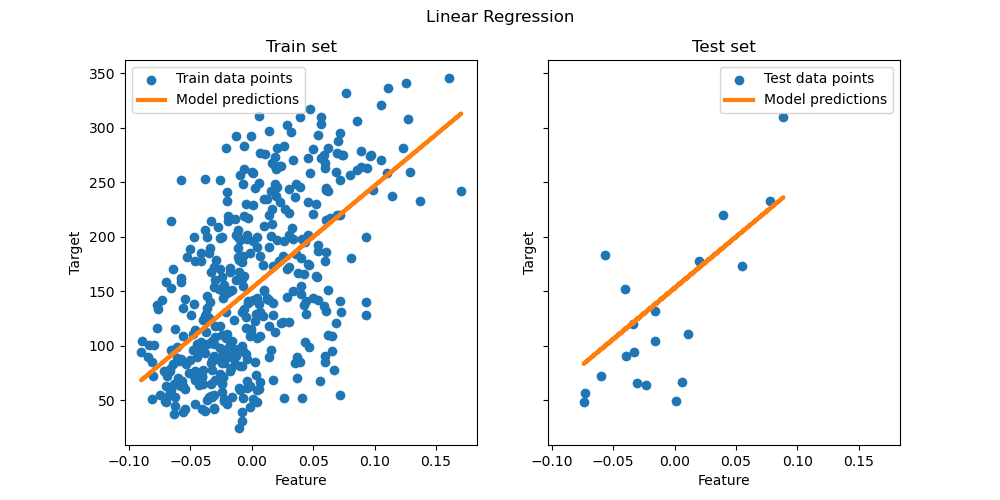
In this figure, X is represented as Feature, and Y is the Target. On the left panel, a linear regression line is used to fit the training data set. Once the linear regression function is learned from the training data, we use it to make predictions on the testing data set on the right panel. Note that, in general, supervised machine learning can learn function for both numeric Y and categorical Y that takes values such as Yes/No. The categorical labels can indicate whether a customer would buy a product from you, or the breed of the dog in a photo you just taken with your phone.
When we apply the linear model, however, we realize the relationship between X and Y in many real-world data is not linear at all. The linear model may work in a very specific subset of the data but the overall relationship and pattern can be extremely complex even in very simple applications. Think about the relationship between the average number of hours worked and the yearly income in our society. This is a typical quadratic relationship: both groups working for few hours and too many hours earn less than the typical group working for 8 hours per day.
How to fit data with such complex relationship patterns? Several classic machine learning algorithms were developed to this end. We will briefly discuss the following examples: Nearest Neighbor, Support Vector Networks, Decision Tree, and Neural Networks.
Nearest Neighbor
Nearest Neighbor is such a simple idea to make predictions without learning a simple linear relationship. Indeed, it does NOT learn any explicit relationship from X to Y. The major computation happens when the model is asked to make decision about a new data: the model would compare the new data to each data point in the training data set, identify a small number of nearest neighbors for the new data, and use the Y values of the nearest neighbors to make decisions about the new data. For numeric problem, we use the average Y values of the neighbors; for categorical problem, we use the majority voting, i.e., the most common Y values of the neighbors. Given its simplicity, the Nearest Neighbor algorithm has been widely used in many applications since 1950s. Even today, it is still an important benchmark algorithm in machine learning research and applications.
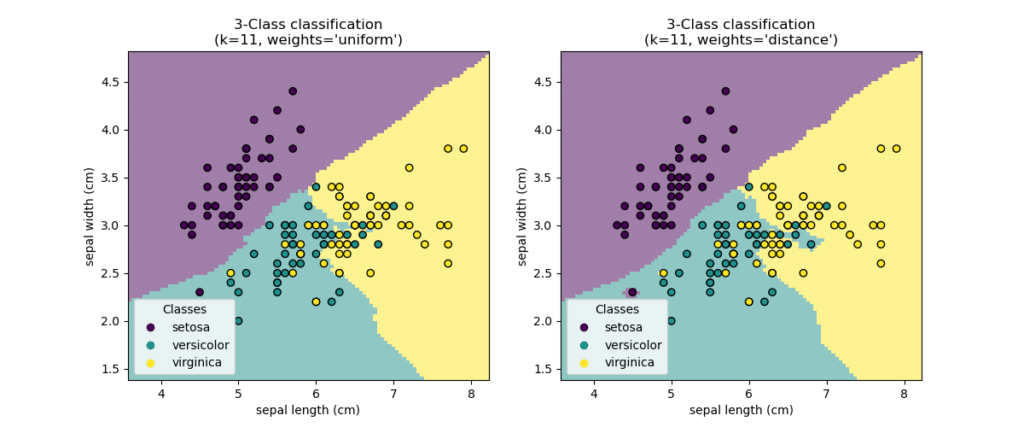
There have been various research directions focusing on the efficiency issue of Nearest Neighbor algorithm. If not properly implemented, the decision-making tasks can be extremely slow. Other models such as linear regression needs only a learned formula to make decisions, but nearest neighbor model needs a lot of data and computation that cannot be accomplished in advance to save decision-making time.
Support Vector Networks
Support Vector Networks (SVNs), also known as Support Vector Machines (SVMs), are one of the most studied machine learning algorithms from 1990s to 2010s (before we switched focus on neural networks and deep learning). SVMs can not only learn linear functions but also perform nonlinear operations efficiently to learn complex relationship patterns that cannot be captured by simple linear regressions.

Although it has “network” in its name, it works very differently with the current deep neural networks. Also don’t be confused by the term “machine” in the name. SVM is a mathematical machine learning model but not a physical machine.
Decision Tree
Another machine learning algorithm often used to learn complex patterns is the decision tree. The basic decision tree algorithm has also been widely extended into more powerful learning algorithms such as Random Forest and XGBoost, which gained much popularity in 2010s.

When looking at a decision tree, a common misunderstanding is that the tree was designed or optimized by some human experts and then computers just follow the tree to make automated decisions. While the 2nd half of this statement is true, the 1st half is completely wrong. Remember, in machine learning, human experts don’t explicitly program the decision making process. Instead, everyone is based on the training data set. In the case of decision tree algorithm, the tree structure itself is automatically constructed based on information and patterns hidden in the training data. This learning process can accommodate nonlinear and interactive relationships that cannot be captured by simple linear models. The extended algorithms, such as random forest, can construct and combine many simple trees to collaboratively capture even more complex relationships.
Neural Networks
Finally, let’s talk about the currently most popular type of machine learning algorithms, the neural networks. The fundamental idea of neural networks is to simulate a biological neural network, where information can travel through a network of biological neurons that are chemically connected to each other by synapses. Other than this biological analogy, a neural network for machine learning is simply a system of many linear functions and nonlinear functions integrated together to approximate the X->Y relationship. The linear functions can aggregate information from many neurons to travel to a neuron node in the next network layer; and the nonlinear functions can transform information within each neuron before sending its information into the next layer aggregation. In the end, all information X is transformed, aggregated, transformed, aggregated, transformed, aggregated, …, and many times later used to predict Y.
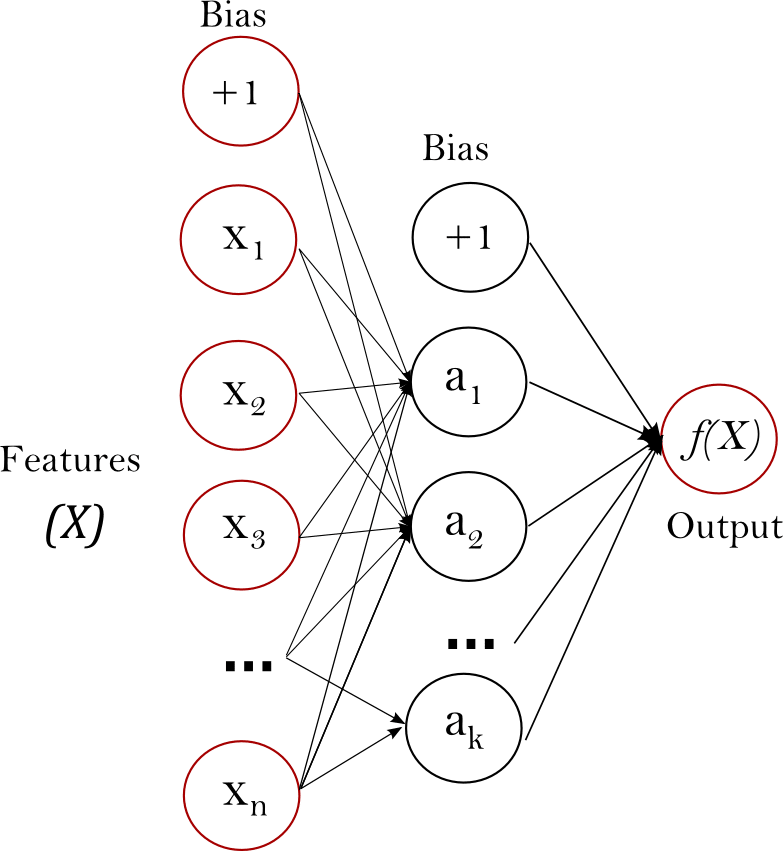
Again, this simple structure has been extended in many ways to learn sequences, graphs, images, videos, and texts. For instance, the Convolutional Neural Network (CNN), can more efficiently capture key information from images to recognize objects, and it has been one important algorithm for today’s technology innovation. Smart cars can recognize vehicles, traffic lights, and road signs by sending the camera videos to a CNN algorithm. In our class, we will work together to build a similar algorithm that can recognize different breeds of dogs.
Unsupervised Learning
So far, this post discusses only few classic supervised learning algorithms. Unsupervised algorithms that can learn patterns in X without any Y, are also important techniques in machine learning and artificial intelligence systems. For instance, just by collecting basic descriptive information about your customers, you can apply clustering algorithm, which is an example of unsupervised machine learning algorithms, to group your customers into coherent clusters and then design customized products and services to each individual cluster. This is well-known as customer segmentation in many customer businesses.
Summary
This post has introduced a few important machine learning algorithms for us to better understand the motivation of developing new algorithms that can improve previous ideas. With advances in technology, business, and society, the key aspects we want to improve have also been changing. We use to focus mostly on accuracy of machine learning algorithms, but now we consider explainability and fairness as important goals. We use to develop algorithms that can run on a single computer, but now we want algorithms that can leverage cloud computing infrastructure. Most importantly, machine learning was a special topic of computer sciences and statistics, but now a universal skill set for many occupations. With the anticipated wide adoption of generative artificial intelligence with machine learning as its backbone, the demand for machine learning experts will become even stronger than we have already seen.
This post mainly introduced the conceptual ideas in several classic machine learning algorithms. Their behaviors, advantages, and limitations will be discussed later when we introduce each of the specific models. This post is definitely not the Complete Chronicles of Machine Learning Theories. There are many other more advanced research topics and applications not mentioned in this short post. However, I hope these are helpful enough to open the door for you to continue learning more.
In the next post, we will continue to discuss other aspects of machine learning history: software, hardware, and data.
Leave a Reply